Remove NA
Strukturierte Daten zur queeren Geschichte
Kontext ist Queen
Das Projekt Remove NA verknüpft Data Science und Domänenwissen mit dem Ziel, queere Daten in das Netz der offenen, verlinkten Daten einzuweben.
Queere Geschichte fehlt in Wissensdatenbanken
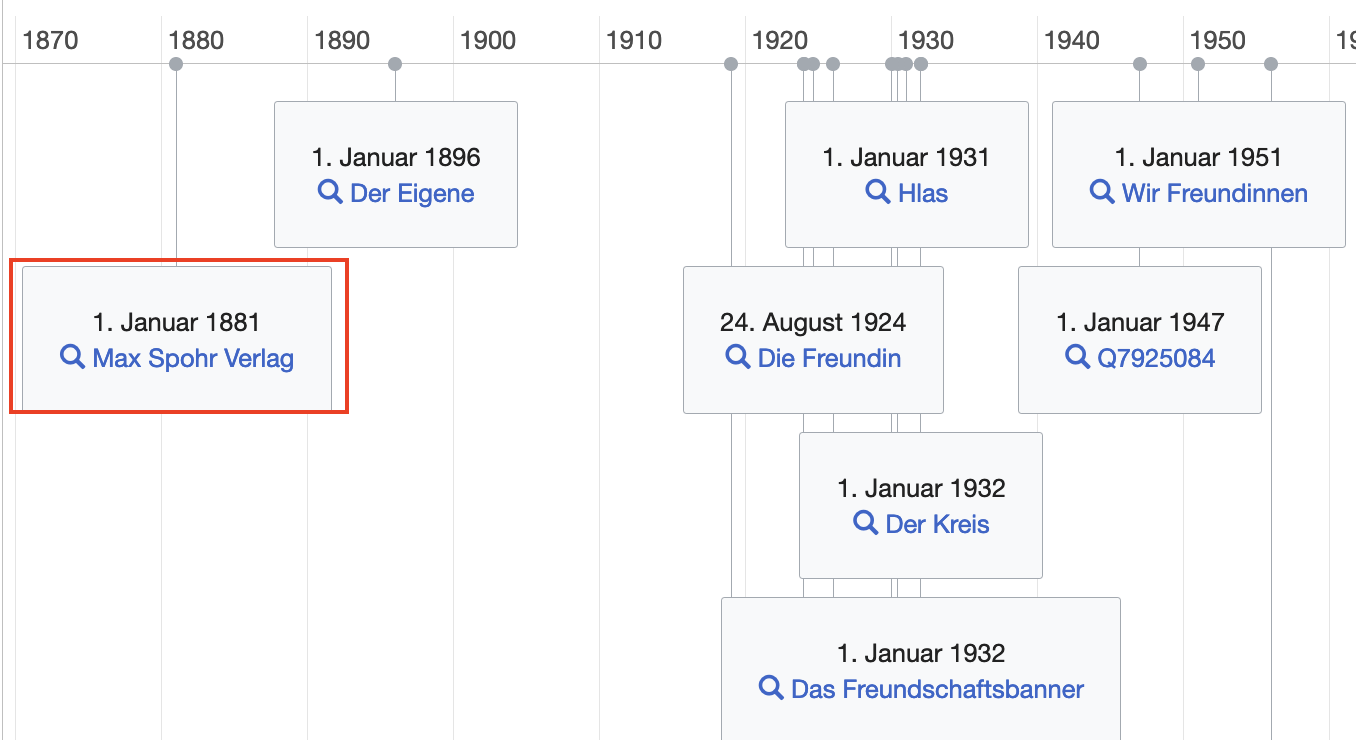
Der Mann auf dem Bild ist Max Spohr. Geboren 1850 in Braunschweig lebte er später vor allem in Leipzig, dem Zentrum der deutschen Buchwelt, Ende des 19. und im angehenden 20. Jahrhundert. Spohr war Verleger und Buchhändler - und jemand, den man heute einen LGBT-Aktivisten nennen würde.

Er war Mitbegründer des Wissenschaftlich-Humanitären Komitees, der allerersten organisierten homosexuellen Interessenvertretung in der Geschichte der Menschheit. Einer der anderen Gründer war ein Mann, der heute deutlich prominenter als Spohr ist - und auch schon damals schon war: Magnus Hirschfeld, Leiter des Instituts für Sexualwissenschaften in Berlin, das die Nationalsozialisten 1933 zerstörten. Spohr dagegen war ein Mann der Bücher, gründete 1891 den Max Spohr Verlag und brachte ab 1893 homosexuelle Emanzipationsliteratur heraus. Spohr war ein Pionier schwuler Literatur.
Albert Knoll (Hrsg.): Die Enterbten des Liebesglücks – Max Spohr (1850–1905), Pionier schwuler Literatur. Hier zu bestellen für 5 Euro plus Versand
Albert Knoll (Hrsg.): Der Anschlag auf Magnus Hirschfeld. Ein Blick auf das reaktionäre München 1920. Hier zu bestellen für 7 Euro plus Versand
Warum hebe ich Spohr heraus? Als ich recherchierte, ob meine These, dass queere Geschichte in den gängigen Wissensdatenbanken fehlt, stimmt, war er der erste Name, den ich in eine Suchmaske schrieb - und gleich einen Treffer. Denn siehe da: In der Normdatei der Deutschen Nationalbibliothek (GND), dem großen und für den Kulturbereich auch sicherlich wichtigsten Datensatz von verlinkten Daten, ist Max Spohr nur mit zwei anderen Verlagen affiliiert. Die Verbindung zwischen Max Spohr und seinem für die Homosexuellenbewegung so wichtigen Verlag fehlt; sie ist NA.

Die englische Abkürzung NA steht für „not available” und wird verwendet, wenn Informationen fehlen. Daten zur Geschichte von nicht-heterosexuellen Menschen sind häufig NA und das, was die nigerianische Künstlerin Mimi Onuoha als “missing data” bezeichnet: „Missing impliziert sowohl einen Mangel als auch ein Sollen: etwas fehlt, sollte aber existieren.”

Queere Geschichte wurde lange Zeit nicht strukturiert erfasst und wenn, dann häufig in Bezug auf Kriminalität oder Perversion. Ab den 1970er Jahren gründeten sich selbstorganisierte Archive (Liste in Wikidata). In München das Forum Queeres Archiv, ein Community-Archiv, das seit 20 Jahren sammelt, forscht und publiziert: Regalmeter voller Nachlässe, Aktenordner, Bücher, Zeitschriften, Objekte ... Das Sammeln ist kein Selbstzweck: Alle können die Materialien vor Ort nutzen – Open Source im Analogen.
Doch in den digitalen Räumen fehlen Daten zur LGBTIQ*-Geschichte weiterhin. Das hat zur Folge, dass sie auch in den Anwendungen fehlt, die darauf aufbauen und die wir Tag für Tag benutzen. Dazu gehören Suchmaschinen, Chatbots oder Sprachassistenten. Ebenso eine unüberschaubare Anzahl von privatwirtschaftlichen, staatlichen und wissenschaftlichen datenbasierter Algorithmen, die direkt mit semantischem Wissen arbeitet oder sie als Trainingsdaten für die Mustererkennung nutzt. Diese Technologien setzen direkt auf Quellen wie etwa Wikidata auf.
Die vergangenen sechs Monate hatte ich das Privileg, daran zu arbeiten, die Sichtbarkeit von Daten zu queerer Geschichte zu erhöhen. Mein vom Prototype Fund gefördertes Projekt Remove NA verwandelt analoge, queere Geschichte in verlinkte offene Daten und gliedert sie ein in eine offene, frei zugängliche, gemeinwohlorientierte Dateninfrastruktur.
Verlinkte Daten in das Netz offenen Wissens einweben
Der beste Weg um Daten und ihre Zusammenhänge und Bedeutungen für Menschen und Maschinen gleichermaßen interpretierbar zu veröffentlichen, sind verlinkte, offene Daten (Linked Open Data, kurz: LOD). Tim Berners-Lee, der Erfinder des World Wide Web, hat diese LOD als oberste Stufe eines Fünf-Sterne-Modells für offene Daten definiert.
Eine Anmerkung zu den Begrifflichkeiten: In diesem Text verwende ich Knowledge Graph, semantische Daten und Linked Open Data synonym, auch wenn mir bewusst ist, dass die Begriffe nicht deckungsgleich sind. Doch sie alle basieren auf dem gleichen Prinzip: Daten und ihre Zusammenhänge formal mit Hilfe von vereinbartem Vokabular hinterlegen, unterschiedliche Datenquellen integrieren und es so möglich machen, verschiedene Aspekte abzufragen.

Auf der Seite Links und Referenzen habe ich unter Knowledge Graphs Podcasts, Online-Kurse, Paper und Tutorials gesammelt, die ich als hilfreich empfand.
Um mit maschineller Hilfe fehlende Daten aufzuspüren, braucht es ein Positiv (den Knowledge Graph zur LGBTIQ*-Geschichte), um durch einen Abgleich mit Linked Open Data das Negativ (die Leerstellen) aufleuchten zu lassen. Die Daten, die es dafür braucht, können auf Grund knapper Ressourcen nur mittels Data Science erkämpft werden. Aus dem Wissen des Forums habe ich Informationen zu verschiedenen Entitäten wie Personen, Orte, Organisationen, Ereignissen, Büchern, Postern gesammelt und diese zueinander in Beziehung gesetzt.
Diesen internen Knowledge Graph konstruierte ich in FactGrid, das sich an ein Fachpublikum, mit akademisch-geschichtswissenschaftlichem Hintergrund richtet. Doch um sicherzustellen, dass die Daten möglichst großen, breitenwirksamen Einfluss haben, kann es nur ein Ziel in der Welt der Linked Open Data geben: Wikidata. Denn Wikidata ist die größte offene Wissensdatenbank mit aktuell 99 Millionen Objekten und das Scharnier schlechthin für externe Datenquellen. Zu jedem Objekt sind meistens nicht nur die Informationen hinterlegt, sondern auch Identifikatoren in andere Datenbanken. Jeder einzelne dieser Identifier ist ein Schlüssel in einen anderen Datensatz.
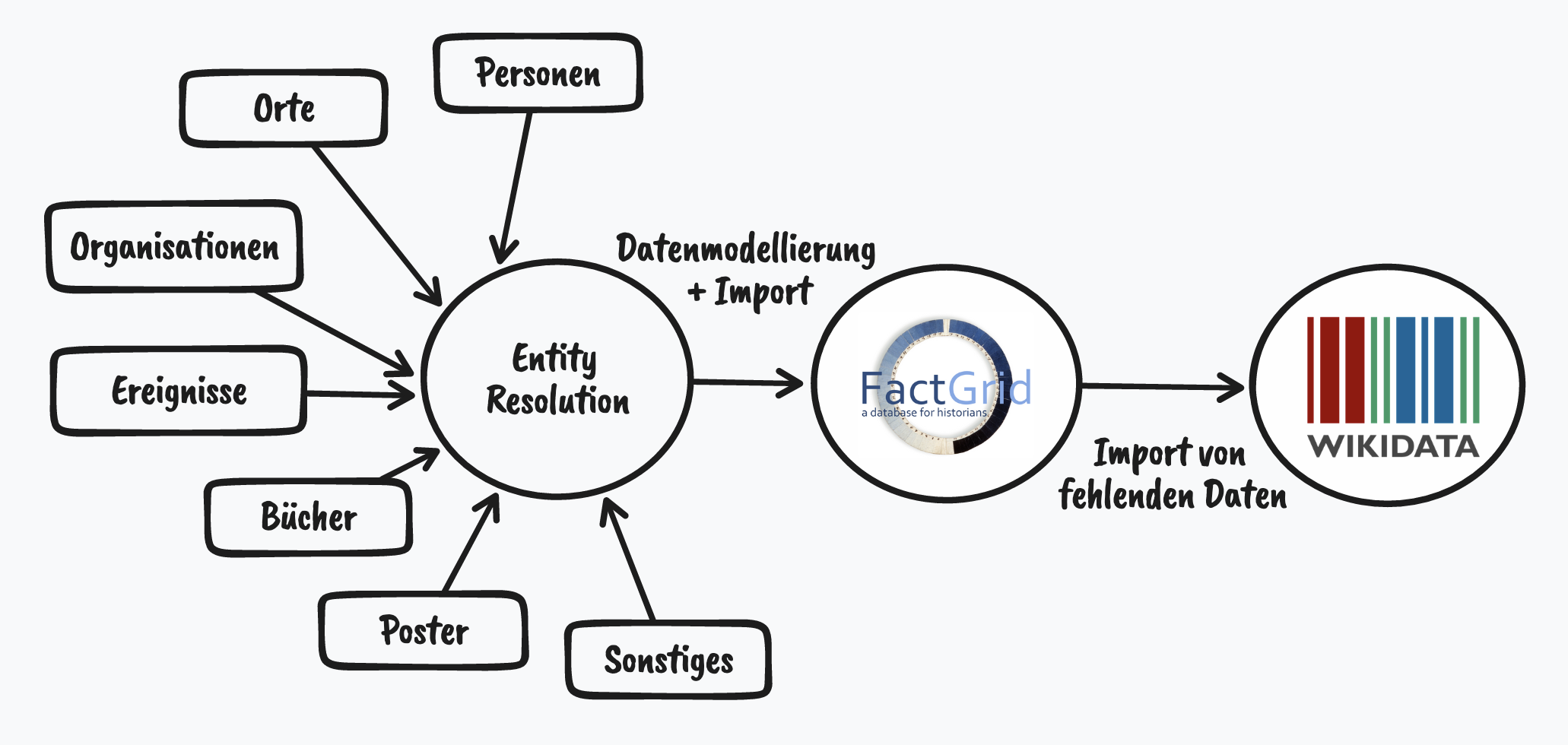
FactGrid gibt es seit 2018, es basiert auf der Wikibase-Software des Wikidata-Projektes. Gegenwärtig nutzen 25 Projekte die Plattform. So werden dort etwa alle Personen und Orte, die in der Bibel und dem Koran vorkommen (Netzwerk aller Personen und ihrer Beziehungen untereinander - Vorsicht vielleicht crasht der Browser, so viele sind es), strukturiert erfasst, die Mitglieder im Illuminatenorden oder Best-Practice-Methoden für die Erfassung von Manuskripten als Open Data. Auch Remove NA ist hier dabei. Das hat zwei große Vorteile: Zum einen brauchte ich keine eigene Infrastruktur aufsetzen - spare also Zeit für meine Kernaufgabe auf - und zum anderen konnte ich von Erfahrungen und Synergien eines kollaborativen Projekts profitieren.
Zwei Beispiele dafür: Bei 40 Personen fand ich bereits Informationen dazu vor, dass sie in der Zeit des Nationalsozialismus aus Deutschland fliehen mussten. Eine Information, die so aus meinem Datensatz nicht hervorgegangen wäre. Ein andermal war ich dabei, die biografischen Daten zu Männern zu importieren, die zwischen 1933 und 1945 auf Grund ihrer Sexualität unter anderem in Konzentrationslagern inhaftiert wurden. In FactGrid waren bereits von Forschenden die “Lager oder Spezialeinrichtungen der nationalsozialistischen Verfolgungs- und Vernichtungspolitik” eingetragen, hier alle auf einer Karte einsehbar.
Im nächsten Schritt glich ich FactGrid und Wikidata miteinander ab: Welche Entitäten gibt es bereits, welche nicht, welche Zusatzinformationen kann ich hinzufügen? Fehlten Inhalte, hab ich sie neu erstellt oder ergänzt.

Man kann sich Wikidata als riesigen Heuhaufen vorstellen. Auf den ersten Blick sieht es nach einer ungeordneten Menge an Information aus. Auf den zweiten Blick gibt es natürlich eine Struktur, die aber je nach Bereich unterschiedlich modelliert sein kann - und damit unterschiedliche Suchanfragen nötig macht. Beispielsweise sind LGBT-Filmfestivals unmittelbar über die wichtigste Wikidata-Eigenschaft “ist ein: LGBT-Filmfestival” auffindbar. Verlage mit vorwiegend queerem Programm dagegen findet man nur mittelbar über eine kombinierte Suche von “ist ein Verlag” und “hat das Genre: Medien mit LGBT-Bezug”.
Sehr wichtig war deshalb die Orientierung an und die Mitarbeit in der Wikidata LGBT-Gruppe, die queere Inhalte kuratiert, Datenmodelle vorschlägt und vereinheitlicht. Dieses Ausrichten an bestehenden Datenmodellen ist ein wichtiger Baustein, um verlinkte Daten möglichst effizient und nachhaltig in das Netz des offenen Wissens einzuweben und die Vergangenheit für die Zukunft zu erhalten.
FactGrid: Why should I use Factgrid for my research project?
Wikidata: WikiLGBT Project
Zahlen, bitte!
Insgesamt konnte ich 7415 Entitäten aus den Datenquellen des Forums Queeres Archiv München extrahieren, die mehr als 38 000 Verbindungen haben. All diese Daten lassen sich als großes Netzwerk zeichnen.

Netzwerke sehen immer beeindruckend aus, doch zur Analyse und zum Eintauchen taugt diese Makroperspektive nicht. Ich halte es für den besseren Zugang, einzelne Aspekte zugänglich zu machen. Ich verstehe sie als Skizzen, um einen Eindruck davon zu geben, welche Perspektiven die Daten enthalten:
- Chronik queerer Geschichte
- München als Zentrum bayerischer LGBTIQ*-Geschichte
- Nationalsozialismus
- Beziehungsgeflechte
- Weggefährt*innen
Die themenspezischen Einblicke ergeben sich aus den Aussagen (“Statements”), die für ein Objekt (“Item”) in FactGrid hinterlegt sind. Etwa, dass die Frauenrechtlerin Anita Augspurg 1857 geboren wurde, mit Lida Gustava Heymann zusammen war, als Juristin arbeitete, in die Schweiz fliehen musste und noch einige mehr. Zusammengezählt sind es 27 Aussagen, inkl. Verweise auf Wiki-Projekte, exklusive Metadaten wie Forum München ID oder das Forschungsprojekt, im Rahmen dessen das Objekt erstellt wurde. Augspurgs Eintrag liegt damit deutlich über dem Durchschnitt von 19. Die meisten liegen im unteren zweistelligen Bereich: Ein kurzer Steckbrief zu Name, Typ (Mensch, Organisation, … ), Gründungsjahr, Ort, Arbeitsgebiet. Die größte Anzahl an Aussagen hat die Deutsche AIDS-Hilfe mit 139, ein Großteil davon basiert auf Postern zur AIDS-Aufklärung und Safer Sex.
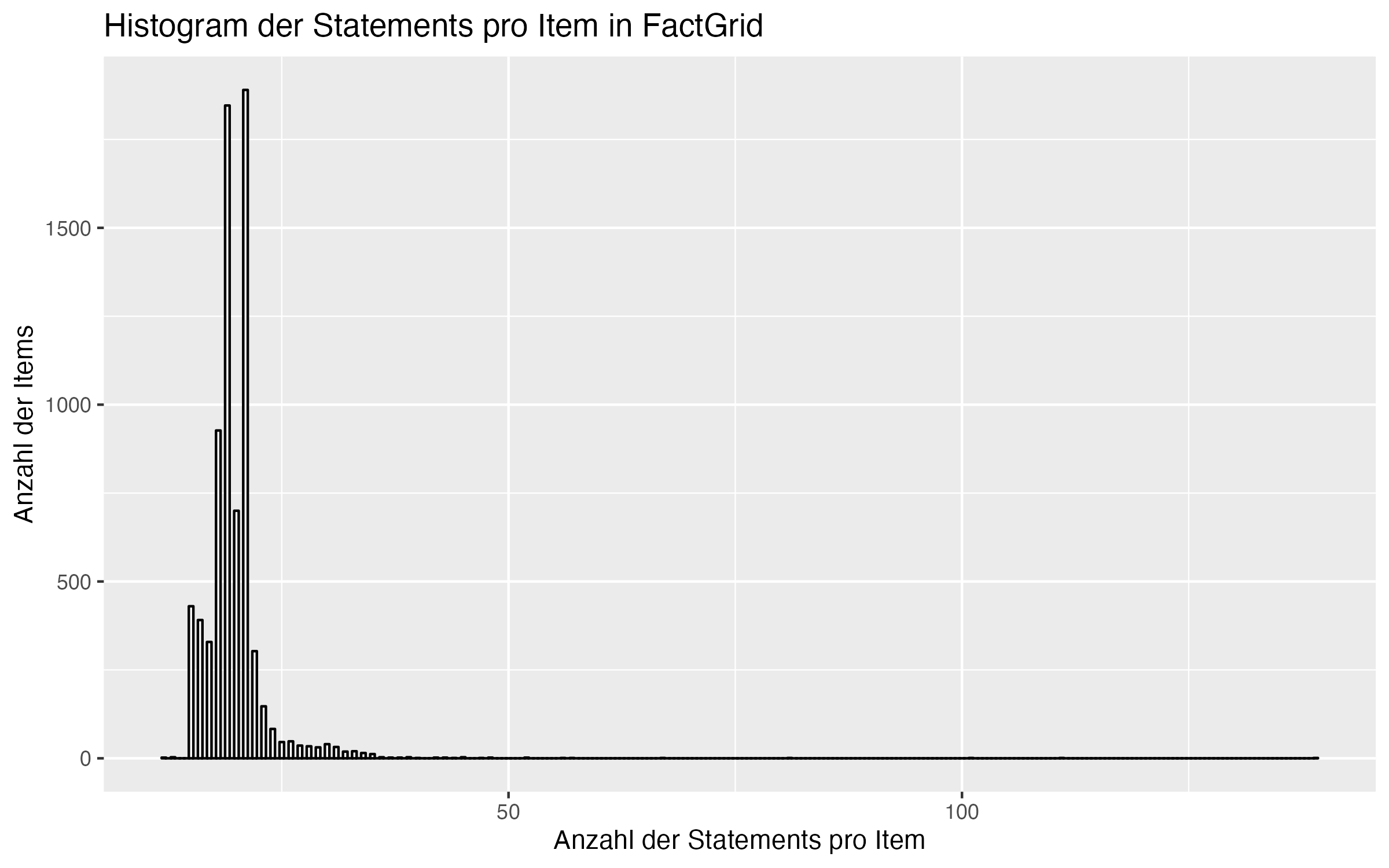
Weite Teile dieser Daten und ihre Beziehungen untereinander habe ich mitsamt ihren zugehörigen Aussagen wie Startdatum, Ort, Auflösungsdatum und vieles mehr nach Wikidata importiert. Weggelassen habe ich einzelne Bücher und Poster. Lücken schließen konnte ich Insbesondere bei kleineren oder lokalen Organisationen, die bisher in Wikidata gar nicht vertreten waren. Und auch bei bekannteren Organisationen fehlten häufig grundlegende Informationen wie Gründungsdatum, Auflösungsdatum, das Arbeitsgebiet usw.
Ein besonders eindrückliches Beispiel ist das Lesbenfrühlingstreffen, ein zentrales, jährlich stattfindendes Treffen der autonomen Lesbenbewegung, das zwar als Objekt angelegt war, aber keinerlei weiterführende Informationen enthielt.
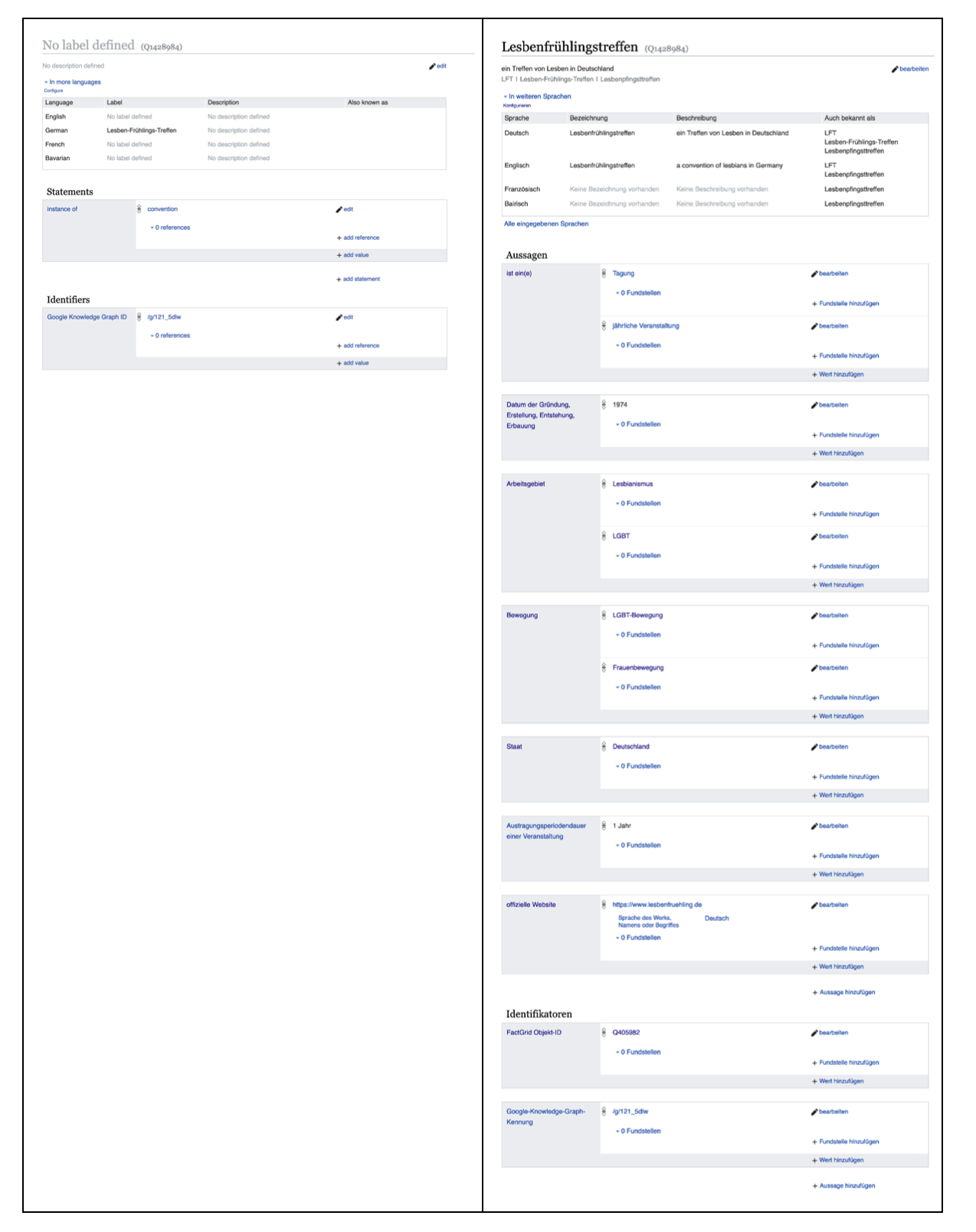
Über Entitäten finden und verbinden, schrieb ich auf meinem Blog.
Die offene und die geschlossene Welt
Daten sind selten vollumfänglich: Menschen oder Maschinen erfassen nicht alles, Daten sind veraltet, haben blinde Flecken, wurden gelöscht, sind vielleicht schlichtweg falsch. Es gibt sehr viele Gründe, wieso Datensätze nicht perfekt sind. Sie alle führen dazu, dass sie die Welt nie exakt abbilden und selbst eine mit vielen Mühen abgetrotzte Vollerfassung ist schneller veraltet als erstellt.
Es gibt zwei Wege damit umzugehen: Entweder man ignoriert bewusst oder unbewusst diesen Umstand der Unvollkommenheit und geht dennoch davon aus, dass Daten die komplette Abbildung der Realität sind. Closed World Assumption ist der Fachausdruck dafür. Die Folge: Was nicht in den Daten ist, darf und kann nicht sein, ist also falsch. Dies ist nur in einem System möglich, das die komplette Kontrolle über die Datenentstehung und Verarbeitungsprozesse hat.
Doch nur weil eine Information, eine Beziehung in den Daten nicht vorhanden ist, heißt das nicht, dass sie in der Realität, außerhalb des Datensatzes, nicht existiert. Hier kommt die Open World Assumption ins Spiel. Nach dieser Annahme kann auch dann etwas wahr sein, wenn es nicht in den Daten vorkommt. Ein Beispiel ist das klassische Telefonbuch, das zumindest bis vor einigen Jahren weite Teile von Haushalten oder Organisationen mit einer Telefonnummer listete. Doch nur weil jemand nicht darin auftauchte, hieß das nicht, dass ein Telefonanschluss nicht existierte.
Remove NA gehört ganz klar in die Kategorie der offenen Welt. Ein Projekt, das Lücken füllt, aber auch selbst welche hat.
Erstens ist eine Vollständigkeit utopisch und zweitens erfordert diese Art der Arbeit viel Zeit, weshalb ich mich in den sechs Monaten Projektlaufzeit um die low hanging fruits gekümmert habe.
Lücken bestehen weiterhin. Es fehlten insbesondere Daten zu bisexuellen und/oder trans Menschen oder Organisationen, in Bezug auf Verfolgung während des Nationalsozialismus liegen fast ausschließlich Informationen zu Männern vor. Geografischer Fokus ist ganz klar München, insbesondere, was die Zeit ab den 1970ern Jahren angeht.
Wer also Lücken (und natürlich Fehler) findet, sei dazu aufgerufen, sie in Wikidata oder in FactGrid selbst zu füllen. Denn das ist die Stärke der kontinuierlichen, kollaborativen Datenkuration.
Abwägung zwischen Modell und Wirklichkeit
An vielen Stellen im Laufe des Projekts habe ich Daten modelliert. Das ist die zentrale Stelle, um Informationen für Maschinen und Menschen gleichermaßen interpretierbar zu machen.
Man versteht darunter die formale Abbildung von Beziehungen und Beschreibungen. Ein gutes Beispiel für ein Modell ist die U-Bahn-Karte einer Stadt für den Zweck, sich möglichst zurechtzufinden und den schnellsten Weg von A nach B zu finden. Sie ist ungeeignet dafür, sich zu Fuß auf den Weg zu machen.
An meinem ersten Tag an der London School of Economics wurde uns dieses Beispiel eines Modells gezeigt: die London Tube Map. Die Abstände zwischen den Stationen stimmen nicht ganz, Strassen sind nicht eingezeichnet, Häuser schon mal gar nicht. pic.twitter.com/oYSCfWZRKS
— Konrad Burchardi (@kbburchardi) March 31, 2022
Ähnlich ist es mit den Modellen für Datenbanken. Es geht darum, Daten möglichst gut abzulegen und wiederzufinden.
Beispiel Geschlechtsidentität: Bei queerer Geschichte handelt es sich dabei nicht um ein weiteres Datenfeld, sondern um einen Kern der Bewegung und einen zentralen Punkt der persönlichen Identität. Kevin Guyan analysiert in seinem Buch “Queer Data: Using Gender, Sex and Sexuality Data for Action” die Datenerhebung und Fragestellung am Beispiel von Zensusbefragungen. Solche Volksbefragungen als staatliches Planungsinstrument zählen Menschen, teilen sie je nach Selbstauskunft in Gruppen ein, und die Politik und Verwaltung treffen basierend auf diesen Daten Entscheidungen. Dabei gibt es ein Spannungsverhältnis zwischen einer möglichst repräsentativen Abbildung der chaotischen Realität und möglichst ordentlichen Daten, die dann aber nicht mehr akkurat sind, mit denen es sich aber leichter arbeiten lässt.
Die Frage nach der Modellierung stellt sich für jede Eigenschaft wieder neu. Die Überlegungen müssen sowohl in der gut sortierten Datenwelt funktionieren als auch in der ungeordneten Realität.
Wenn trans Frauen nicht mehr auftauchen in einer Abfrage nach Frauen, ist das dann das, was ich will oder gerade das Gegenteil? Sollen meine Items nur von Personen gefunden werden, die die queere Welt mitdenken, oder sollen diejenigen, die das nicht tun, queere Inhalte trotzdem finden?
Eine Taxonomie mit dem Zweck, Daten zu lagern, abzufragen und so neu zusammenzustellen, wird unbrauchbarer, je näher es an der messy Realität ist. Gleichzeitig darf die Abstraktion natürlich nicht zu hoch werden, sonst lassen sich keine Schlüsse mehr ziehen.
Die Modellierung von Daten passiert nicht isoliert, sondern meist innerhalb eines bestehenden Systems. Im Falle von Remove NA in zwei Systemen, dem von FactGrid und dem von Wikidata. In FactGrid war das Thema, bis auf weiblich und männlich, nicht bearbeitet. Dort hatte ich freie Hand, mir eine Systematik auszudenken, die mir als schlüssig erschien. Wikidata ist dagegen ein seit zehn Jahren gewachsenes System mit (meist) etablierten Wegen, um Geschlecht zu modellieren.
In der Frage der Geschlechtsidentität einigte ich mich mit mir selbst auf dieses Modell (Discuss!):

Buch: Kevin Guyan, Queer Data: Using Gender, Sex and Sexuality Data for Action, Bloomsbury Academic, 2022
Twitter Thread zu: “As a non-binary historian of medieval women my real take on non-binary Joan of Arc is that literally any time we prescribe a gender label to someone in the past we are making an assumption that is muddied by modern conceptions of the gender binary.”
Data Science und Domänenwissen: Es braucht beides
Datenprojekte wie Remove NA können nur bis zu einem gewissen Grad als technische Aufgabe begriffen werden. Neben der Datenmodellierung zeigt sich das auch bei der Verbindung von unterschiedlichen Datensätzen ohne gemeinsamen Identifikator. Beispiel: Ist “Max Spohr” in meiner einen Tabelle identisch mit “M. Spohr”?
Ein prototypischer Ablauf kann sein: Ist der Name gleich? Oder fast gleich? Gibt es andere Eigenschaften, wie Wohnort oder Geburtsjahr, die eine Identifizierung zulassen? Und wie groß darf eine Abweichung sein, um dennoch noch als Treffer zu gelten? Entscheidend ist auch: Wie groß ist der Kandidatenpool? Könnten in den Daten alle Personen in Deutschland vorkommen, ist die Wahrscheinlichkeit gering, dass es sich bei “M. Spohr” um den Verleger Max Spohr handelt. Suche ich aber eh nur innerhalb von Verlegern des frühen 20. Jahrhunderts, ist die Wahrscheinlichkeit dagegen recht hoch.
Um solche Fragen zu lösen, gibt es regelbasierte oder probabilistische Methoden, auch solche des maschinellen Lernens - oder Kombinationen davon. Allen gemein ist, dass eine Grenzwert definiert werden muss, bei dem eine Übereinstimmung angenommen werden kann. Üblicherweise muss sie umso strenger sein, je wichtiger die Datenqualität in einem Projekt ist. Bis zu einem gewissen Grad kann dieses Entity Linking also maschinell erfolgen, doch bei unsicheren Fällen braucht es Fachwissen, um Entscheidungen treffen zu können, um Personen oder Organisationen zweifelsfrei zu identifizieren. Kurz: Es braucht ein menschliches Gehirn. Manche Fälle sind für uns Menschen sofort zu beantworten, für andere braucht es zusätzliche Recherche.
Für mich überraschend war, dass ich - nach Ansätzen mit einem selbstprogrammierten Werkzeug - auf Software setzte, die ich in meinen Anfangsjahren als Datenjournalistin einige Male benutzt habe und deren Aussehen sich seitdem nicht verändert hatte: Open Refine. Insbesondere im Zusammenspiel mit Wikibase, der Software hinter Wikidata und FactGrid, ergibt sich so ein überzeugendes Paket, um auch die menschlichen Entscheidungen in einen Workflow einzubinden, ohne einzelne Excel-Daten hin und her zu schieben oder händisch eine Datenbank zu editieren.
In einem Datenprojekt verknüpft man also nicht nur Datensätze miteinander, sondern verschränkt auch Data-Science-Methoden mit Domänenwissen. Die Aufgabe von Datenspezialist*innen besteht dann in meinen Augen auch darin, diesen “human in the loop”-Prozess möglichst effizient zu gestalten.
Es entbehrt nicht einer gewissen Ironie, dass dieser Task so unterschiedliche Namen hat.
Theorie
Uni Mannheim: Slides zu Identity Resolution
Linksammlung auf Stackoverflow: Record Linkage Ressources
LMU München: Einstieg in Record Linkage
Praxis
Open Sanctions: How we deduplicate companies and people across data sources
Remove NA: Entitäten finden, Duplikate vermeiden
Daten im Kontext
Alle Personen, die sich in diesem Datensatz zur queeren Geschichte befinden, existierten nicht für sich allein. Sie waren und sind umgeben von Menschen, die sie lieben, mit denen sie zusammenarbeiten, von denen sie verfolgt wurden, mit Menschen, von denen sie beeinflusst und solchen, die von ihnen inspiriert wurden. Kurzum: ihre Weggefährt*innen.
Nimmt man nur die Daten aus Remove NA, wird man diesem Beziehungsgeflecht nicht gerecht. Erst im Zusammenspiel mit anderen Datenquellen kann man sich der Realität halbwegs annähern. Sinnvoll ist es, Wikidata und Wikipedia zu verbinden. DBpedia ist ein Knowledge Graph, der von Wikipedia abgeleitet und mehrmals im Jahr aktualisiert wird.
Ein Beispiel: Bei Magnus Hirschfeld weiß man von zwei Partnern, Karl Giese und Li Shiu Tong. Beide werden im Fließtext in Wikipedia erwähnt, doch in den strukturierten Daten ist das anders. Der eine, Karl Giese, war nur in Wikipedia/DBpedia hinterlegt, der andere, Li Shiu Tong, bis zum Juli 2022 nur in Wikidata. Bis die Lücke geschlossen wurde, musste man beide Quellen abfragen.
Um die Abfrage zu persönlichen Beziehungen zwischen Menschen zu erleichtern, habe ich diese Anwendung gebaut:

Verknüpfte, offene Daten und Wissensgraphen entfalten ihre volle Wirkung, wenn sie miteinander verbunden sind. In der Fachsprache wird dies als Federation bezeichnet. Eine Abfrage über mehrere Datenquellen ist dann eine federated query. So wird beispielsweise ein Eintrag aus FactGrid mit dem entsprechenden Eintrag in Wikidata verknüpft, um ergänzende Informationen abzurufen. Auf diese Weise entfallen redundante Daten in zwei verschiedenen Datenquellen, die im Zweifelsfall nicht synchronisiert sind.
Lücken füllen kann also auch heißen, bestehende Datenquellen klug zu verknüpfen.
Und was ist mit Max Spohr?
Max Spohrs Verlag, den er 1891 gründete und in dem er schwule Literatur herausgab, ist nun in Wikidata hinterlegt. Fragt man nach queeren Verlagen und ihren Gründungsjahren, ist er momentan der älteste unter ihnen. Das ist eine von mehr als 11 000 geschlossenen Lücken.
Erkunde die Daten
Zugang zu den Daten
Alle Daten, die in dem Projekt aufbereitet wurden, finden sich offen zugänglich in zwei Datenbanken:
- Wikidata: Die größte frei zugängliche Datenbank für strukturiertes Daten. Das Wikipedia für Informationen.
- Factgrid: Eine Datenbank für historische Projekte.
Beide Datenbanken basieren auf der Wikibase-Software und verfügen deshalb über einen SPARQL-Endpoint, über den Daten abgerufen werden können.
Bei Fragen, gerne per E-Mail melden melden.
Dank
Das Projekt wurde gefördert vom Prototype Fund und dem Bundesministerium für Bildung und Forschung.
![]()
![]()
Besonders danken für ihre Unterstützung möchte ich: Martina Schories, Linda Strehl, Albert Knoll, Christine Schäfer, Ariane Rüdiger, Olaf Simons und Lucas Werkmeister.