Remove NA
A knowledge graph about queer history
Context is Queen
The Remove NA project links data science and domain knowledge with the goal of weaving queer data into the web of open, linked data.
Queer history missing from knowledge databases
The man in the picture is Max Spohr. Born in Braunschweig in 1850, he later lived primarily in Leipzig, the center of the German book world, in the late 19th and early 20th centuries. Spohr was a publisher and bookseller - and someone who today would be called an LGBT activist.

He was a co-founder of the Scientific Humanitarian Committee, the very first organized homosexual advocacy group in human history. One of the other founders was a man who is much more prominent today than Spohr - and was even then: Magnus Hirschfeld, head of the Institut für Sexualwissenschaft (“Institute for sex research”) in Berlin, which the National Socialists destroyed in 1933. Spohr, on the other hand, was a man of books, founding the Max Spohr Verlag in 1891 and publishing homosexual emancipation literature from 1893. Spohr was a pioneer of gay literature.
Both books are in German.
Albert Knoll (Hrsg.): Die Enterbten des Liebesglücks – Max Spohr (1850–1905), Pionier schwuler Literatur. Hier zu bestellen für 5 Euro plus Versand
Albert Knoll (Hrsg.): Der Anschlag auf Magnus Hirschfeld. Ein Blick auf das reaktionäre München 1920. Hier zu bestellen für 7 Euro plus Versand
Why am I highlighting Spohr? When I researched whether my hypothesis that queer history is missing in the open knowledge databases, he was the first name I wrote into a search mask - and it was immediately a hit. Lo and behold: In the Normdatei der Deutschen Nationalbibliothek (GND), the large and for the German cultural sector certainly most important dataset of linked data, Max Spohr is only affiliated with two other publishers. The link between Max Spohr and his publishing house, so important for the homosexual movement, is missing; it is NA.

Queer history was not recorded in a structured way for a long time, and when it was, it was often in relation to crime or perversion. Starting in the 1970s, self-organized archives (list in Wikidata) were founded. In Munich the Forum Queeres Archiv, a community archive, has been collecting, researching, and publishing for 20 years: Shelf meters full of bequests, files, books, journals, objects …. Collecting is not an end in itself: all can use the materials on site – open source in the analog world.
But data on LGBTIQ* history continues to be lacking in digital spaces. As a result, it is also missing from the applications that build on it and that we use every day. These include search engines, chatbots, or voice assistants. So do an incalculable number of private sector, government, and academic data-based algorithms that work directly with semantic knowledge or use it as training data for pattern recognition. These technologies rely directly on sources such as Wikidata.
For the past six months, I have had the privilege of working to increase the visibility of queer history data. My project, funded by the Prototype Fund, Remove NA, transforms analog queer history into linked open data and incorporates it into an open, freely accessible, public good data infrastructure.
Weaving linked data into the web of open knowledge
The best way to publish data and its connections and meanings in a way that can be interpreted by humans and machines alike is linked open data (LOD for short). Tim Berners-Lee, the inventor of the World Wide Web, has defined this LOD as the top level of a five star model for open data.
A note on terminology: In this text, I use Knowledge Graph, semantic data, and Linked Open Data interchangeably, even though I realize that the terms are not congruent. But they are all based on the same principle: formally store data and their relationships using agreed vocabulary, integrate different data sources, and thus make it possible to query different aspects.

In order to detect missing data with the help of a machine, a positive (the knowledge graph on LGBTIQ* history) is needed in order to illuminate the negative (the blanks) through a comparison with Linked Open Data. Due to scarce resources, the data it takes to do this can only be wrangled through Data Science. From the knowledge of the queer archival association in Munich, I collected information on various entities such as people, places, organizations, events, books, posters, and related them to each other.
I constructed this internal Knowledge Graph in FactGrid, which is aimed at a specialized audience, with an academic history background. But to ensure that the data has the greatest possible broad impact, there can only be one goal in the world of Linked Open Data: Wikidata. After all, Wikidata is the largest open knowledge database with currently 99 million objects and the hinge par excellence for external data sources. For each object there are mostly not only the information stored, but also identifiers to other databases. Each of these identifiers is a key to another data set.
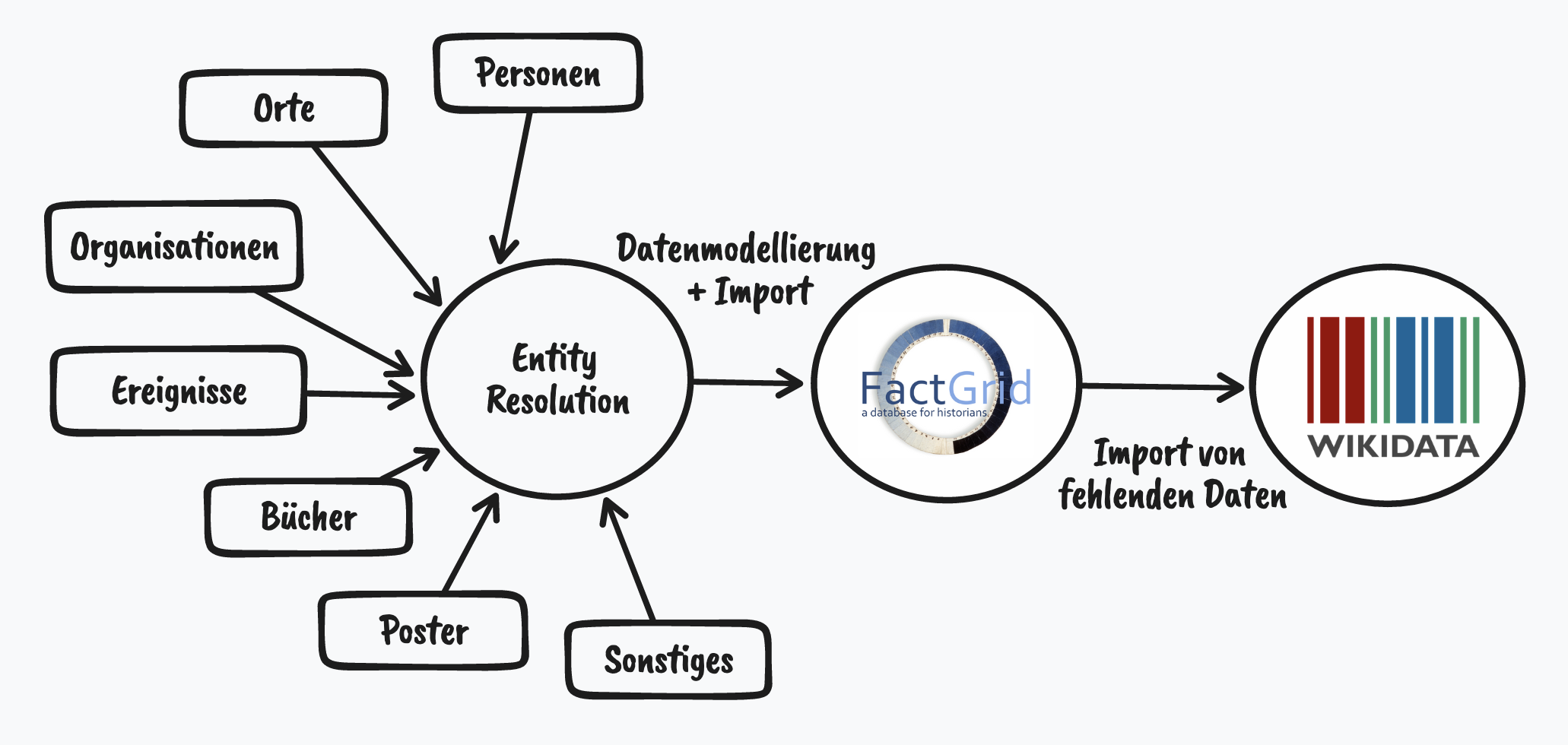
FactGrid has been around since 2018, it is based on the Wikibase software of the Wikidata project. Currently, 25 projects use the platform. For example, all persons and places that appear in the Bible and the Quran (see a network of all persons and their relationships with each other - be careful, your browser might crash, there are so many relations) are recorded in a structured way, the members in the Illuminati Order. Also Remove NA is included here. This has two big advantages: First, I didn’t need to set up my own infrastructure - saving time for my core task - and second, I was able to benefit from the experience and synergies of a collaborative project.
Two examples: For 40 people, I already found information that they had to flee Germany during the National Socialist era. This is information that would not have come out of my data set. Another time I was in the process of importing the biographical data on men who were imprisoned in concentration camps between 1933 and 1945 because of their sexuality, among other things. Researchers had already entered the “Camp or specialised facility of the Third Reich’s persecution and extermination apparatus” in FactGrid, see all on a map.
In the next step, I compared FactGrid and Wikidata: which entities already exist, which do not, what additional information can I add? If content was missing, I created or added it.

You can imagine Wikidata as a huge haystack. At first glance, it looks like a disorganized mass of information. At second glance, of course, there is a structure, but it may be modeled differently depending on the area - and thus require different search queries. For example, LGBT film festivals are immediately accessible via the main Wikidata property “is a: LGBT film festival”. Publishers with predominantly queer content, on the other hand, can only be found indirectly via a combined search of “is a: publisher” and “has the genre: LGBT-related media.”
Very important, therefore, was the orientation to and participation in the Wikidata LGBT group, which curates queer content, proposes and standardizes data models. This alignment with existing data models is an important component of weaving linked data into the web of open knowledge as efficiently and sustainably as possible, and preserving the past for the future.
FactGrid: Why should I use Factgrid for my research project?
Wikidata: WikiLGBT Project
Numbers, please!
In total I was able to extract 7415 entities from the data sources of the Forum Queeres Archiv München, which have more than 38,000 connections. All this data can be drawn as a large network.

Networks always look impressive, but this macro perspective is not suitable for analysis and immersion. I think the better approach is to make individual aspects accessible. I understand them as sketches to give an impression of what perspectives the data contain.
- Chronicle of queer history
- Munich as a center of Bavarian LGBTIQ* history
- National Socialism
- Relations
- Companions
The topic-specific insights result from the statements (“Statements”) that are stored for an object (“Item”) in FactGrid. For example, that the women’s rights activist Anita Augspurg was born in 1857, was together with Lida Gustava Heymann, worked as a lawyer, had to flee to Switzerland and some more. Added together, there are 27 statements, including references to wiki projects, exclusive metadata such as Forum Munich ID or the research project in the context of which the object was created. Augspurg’s entry is thus well above the average of 19. Most are in the lower two-digit range: a short profile on name, type (person, organization, … ), founding year, location, field of work. The Deutsche AIDS-Hilfe has the largest number of statements with 139, much of it based on posters on AIDS education and safer sex.
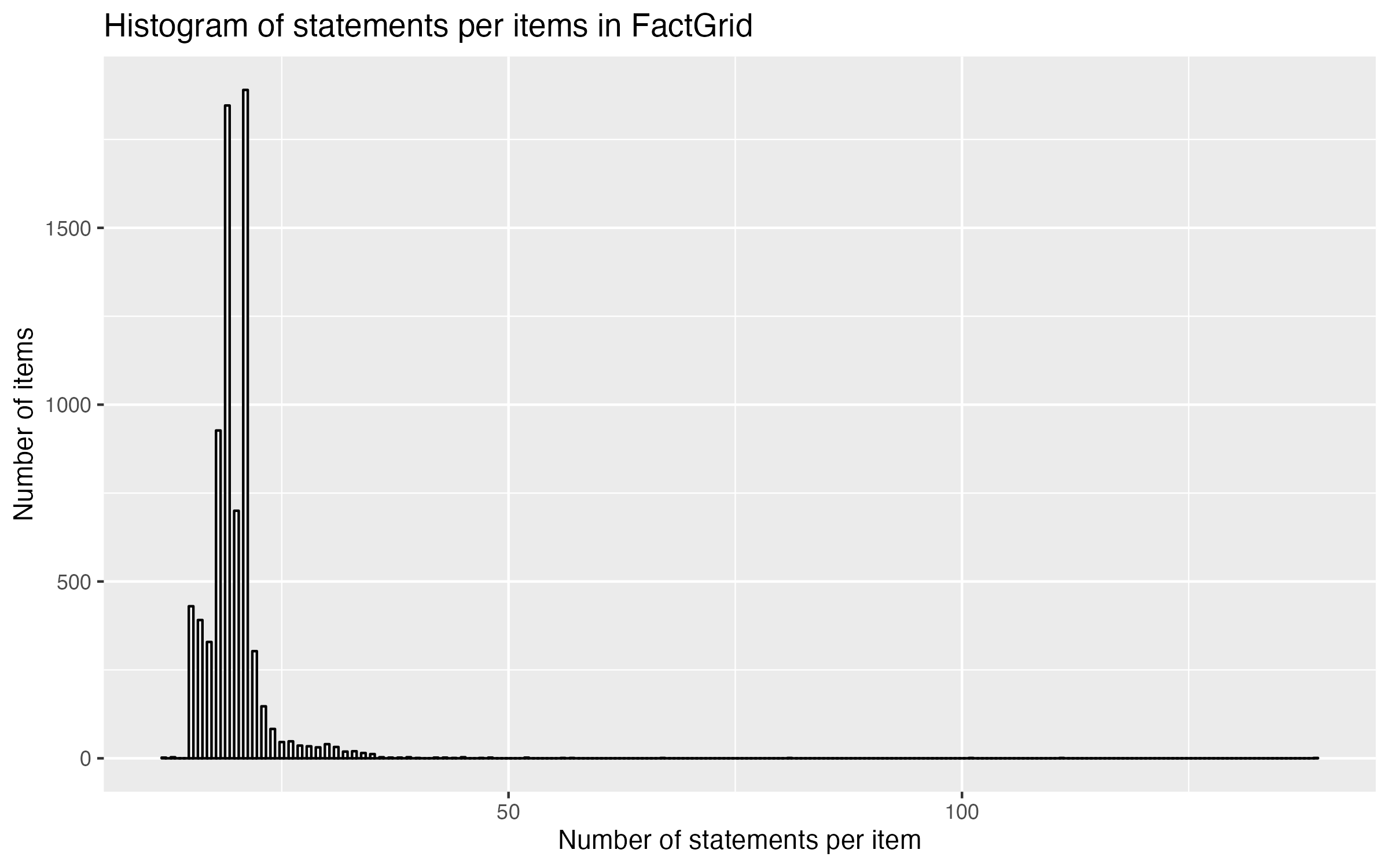
I have imported large parts of these data and their relations among each other together with their associated statements such as start date, location, dissolution date and much more to Wikidata. I left out single books and posters. I was able to fill gaps especially for smaller or local organizations, which were not represented in Wikidata so far. And even for better known organizations, basic information such as the date of foundation, the date of dissolution, the field of work, etc. was often missing.
A particularly impressive example is the Lesbenfrühlingstreffen, a central, annual meeting of the autonomous lesbian movement, which was created as an object, but did not contain any further information.
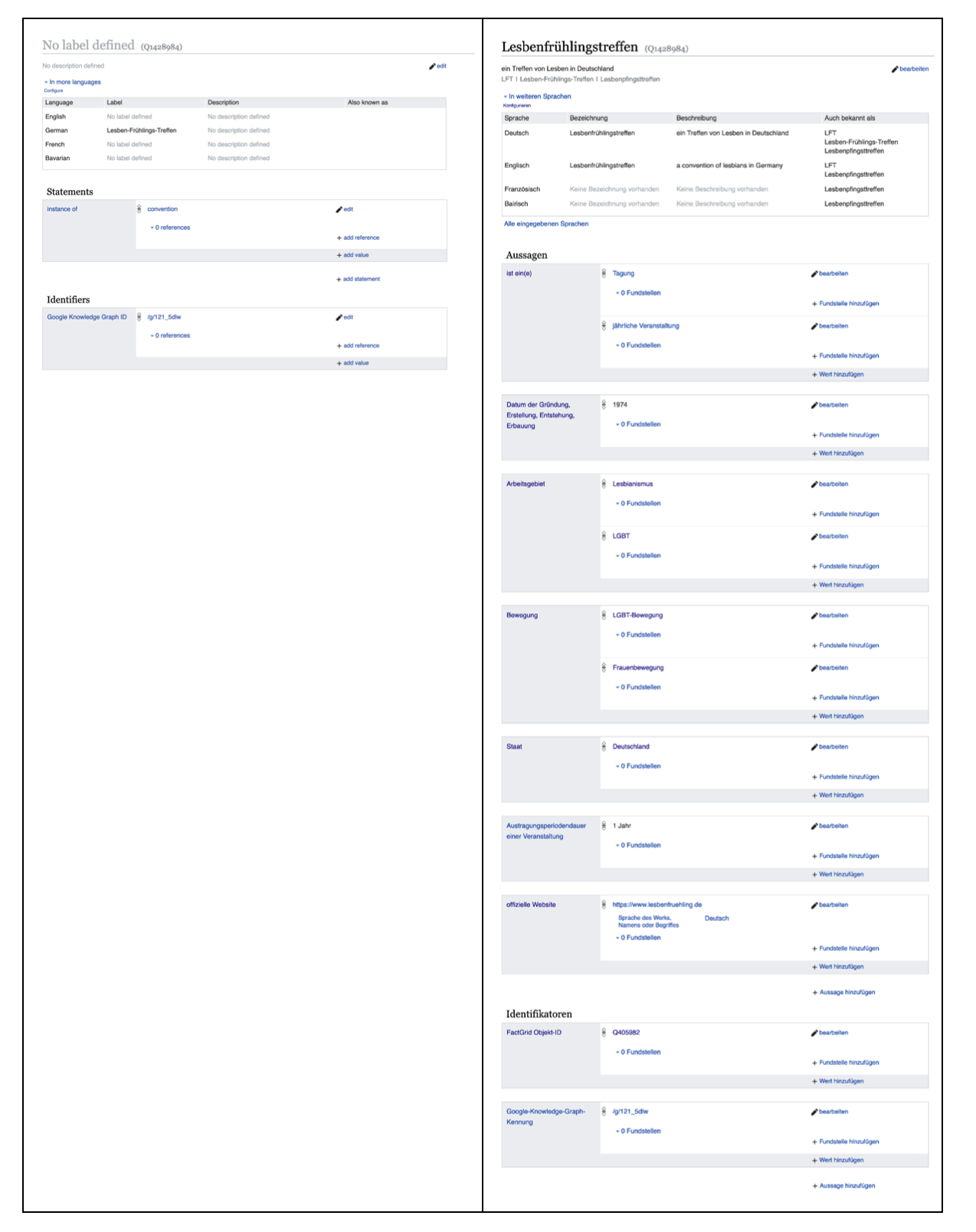
A blog post about finding and connecting entities (in German).
The open world and the closed world
Data is rarely fully comprehensive: humans or machines don’t capture everything, data is out of date, has blind spots, has been deleted, may just be plain wrong. There are many reasons why data sets are not perfect. They all lead to the fact that they never represent the world exactly and even a full capture, which has been achieved with a lot of effort, is outdated faster than it has been created.
There are two ways to deal with this: Either consciously or unconsciously ignore this fact of imperfection and still assume that data is the complete representation of reality. Closed world assumption is the technical term for this. The consequence: What is not in the data must not and cannot be, is therefore wrong. This is only possible in a system that has complete control over data creation and processing.
However, just because a piece of information, a relationship, is not present in the data does not mean that it does not exist in reality, outside of the data set. This is where the Open World Assumption comes into play. According to this assumption, something can be true even if it does not occur in the data. An example is the classic telephone directory, which, at least until a few years ago, listed large parts of households or organizations with a telephone number. But just because someone did not appear in it did not mean that a telephone line did not exist.
Remove NA clearly belongs in the open world category. A project that fills in gaps, but also has some of its own.
First, completeness is utopian, and second, this kind of work requires a lot of time, which is why I took care of the low hanging fruits during the six months of the project.
Gaps still exist. In particular, there was a lack of data on bisexual and/or trans people or organizations; with regard to persecution during National Socialism, there is almost exclusively information on men. Geographical focus is clearly Munich, especially concerning the time from the 1970s on.
So anyone who finds gaps (and of course errors) is encouraged to fill them in Wikidata or in FactGrid itself. Because that’s the power of continuous, collaborative data curation.
Balancing model and reality
At many points during the project, I modeled data. This is the central place for making information interpretable by machines and humans alike.
It is understood as the formal mapping of relationships and descriptions. A good example of a model is the subway map of a city for the purpose of finding your way around as much as possible and finding the fastest way from A to B. It is not suitable for finding your way around. It is unsuitable for setting out on foot.
An meinem ersten Tag an der London School of Economics wurde uns dieses Beispiel eines Modells gezeigt: die London Tube Map. Die Abstände zwischen den Stationen stimmen nicht ganz, Strassen sind nicht eingezeichnet, Häuser schon mal gar nicht. pic.twitter.com/oYSCfWZRKS
— Konrad Burchardi (@kbburchardi) March 31, 2022
It is similar with the models for databases. It’s about storing and retrieving data as well as possible.
Take gender identity, for example: in queer history, this is not just another field of data, but a core of the movement and a central point of personal identity. Kevin Guyan, in his book “Queer Data: Using Gender, Sex and Sexuality Data for Action” analyzes data collection and questioning using census surveys as an example. Such census surveys, as a government planning tool, count people, divide them into groups according to self-report, and policymakers and administrators make decisions based on this data. There is a tension between the most representative model of a chaotic reality and the tidiest possible data, which are then no longer accurate, but with which it is easier to work.
The question of modeling arises anew for each property. The considerations have to work in the well sorted data world as well as in the disordered reality.
If trans women no longer show up in a query for women, is that what I want or just the opposite? Do I want my items to be found only by people who think the queer world along, or do I want those who don’t to find queer content anyway?
A taxonomy with the purpose of storing, querying, and thus reassembling data becomes more useless the closer it is to messy reality. At the same time, of course, the abstraction must not get too high, or no conclusions can be drawn.
Modeling data does not happen in isolation, but usually within an existing system. In the case of Remove NA in two systems, that of FactGrid and that of Wikidata. In FactGrid, except for female and male, the topic had not been worked on. There I had a free hand to come up with a systematics that seemed conclusive to me. Wikidata, on the other hand, is a decade-old system with (mostly) established ways to model gender.
On the question of gender identity, I agreed with myself on this model (Discuss

Book: Kevin Guyan, Queer Data: Using Gender, Sex and Sexuality Data for Action, Bloomsbury Academic, 2022.
Twitter thread about: “As a non-binary historian of medieval women my real take on non-binary Joan of Arc is that literally any time we prescribe a gender label to someone in the past we are making an assumption that is muddied by modern conceptions of the gender binary.”
Data Science meets Domain Knowledge
Data projects like Remove NA can only be understood as a technical task to a certain extent. In addition to data modeling, this is also evident in connecting disparate data sets without a common identifier. Example: Is “Max Spohr” in my one table identical to “M. Spohr”?
A prototypical flow can be: Is the name the same? Or almost the same? Are there other characteristics, like place of residence or year of birth, which allow an identification? And how large may a deviation be in order to still be considered a hit? Also crucial is: How large is the candidate pool? If all persons in Germany could appear in the data, the probability that “M. Spohr” is the publisher Max Spohr is low. But if I search only within publishers of the early 20th century anyway, the probability is quite high, on the other hand.
To solve such questions, there are rule-based or probabilistic methods, also those of machine learning - or combinations of them. What they all have in common is that a threshold must be defined at which a match can be assumed. Typically, the more important data quality is in a project, the stricter it must be. So, to a certain extent, this entity linking can be done by machine, but for uncertain cases, it needs expertise to make decisions to identify people or organizations beyond doubt. In short, it needs a human brain. Some cases are immediately answerable to us humans, for others it takes additional research.
What was surprising for me was that - after approaches with a self-programmed tool - I relied on software that I had used a few times in my early years as a data journalist and whose appearance had not changed since: Open Refine. Especially when combined with Wikibase, the software behind Wikidata and FactGrid, this makes for a compelling package for incorporating human decision-making into a workflow as well, without having to shuffle individual Excel data back and forth or manually edit a database.
So in a data project, you’re not just linking data sets together, you’re also intertwining data science methods with domain knowledge. In my opinion, the task of data specialists is to make this “human in the loop” process as efficient as possible.
It is not without a certain irony that this task has such different names.
Theory
Uni Mannheim: Slides on Identity Resolution
Link collection on Stackoverflow: Record Linkage Resources
LMU Munich: Getting Started with Record Linkage
Practice
Open Sanctions: How we deduplicate companies and people across data sources
Remove NA: Find entities, avoid duplicates
Data in context
All of the individuals in this queer history dataset did not exist on their own. They were and are surrounded by people they love, people they collaborated with, people they were followed by, people they were influenced by, and people who were inspired by them. In short: their companions.
If you only take the data from Remove NA, you will not do justice to this network of relationships. Only in interaction with other data sources can one get halfway close to reality. It makes sense to connect Wikidata and Wikipedia. DBpedia is a Knowledge Graph derived from Wikipedia and updated several times a year.
For example, Magnus Hirschfeld is known to have two partners, Karl Giese and Li Shiu Tong. Both are mentioned in the body text in Wikipedia, but it is different in the structured data. One, Karl Giese, was deposited only in Wikipedia/DBpedia, the other, Li Shiu Tong, until July 2022 only in Wikidata. Until the gap was closed, one had to query both sources.
To facilitate the query on personal relationships between people, I built this application:

Linked, open data and knowledge graphs develop their full effect when they are connected with each other. In technical terms, this is referred to as federation. A query across multiple data sources is then a federated query. For example, an entry from FactGrid is linked to the corresponding entry in Wikidata to retrieve supplementary information. This eliminates redundant data in two different data sources, which in case of doubt are not synchronized.
So filling gaps can also mean cleverly linking existing data sources.
And what about Max Spohr?
Max Spohr’s publishing house, which he founded in 1891 and in which he published gay literature, is now imported in Wikidata. If you query for queer publishers and their founding years, he is currently the oldest among them. This is one of more than 11,000 gaps closed.
Explore the data
Data access
All data processed in the project can be found openly accessible in two databases:
- Wikidata: The largest open-access database of structured data. The Wikipedia for information.
- Factgrid: A database for historical projects.
Both databases are based on the Wikibase software and therefore have a SPARQL endpoint through which data can be retrieved.
If you have any questions, please email.
Acknowledgement
The project was supported by the Prototype Fund and the German Federal Ministry of Education and Research.
![]()
![]()
I would especially like to thank Martina Schories, Linda Strehl, Albert Knoll, Christine Schäfer, Ariane Rüdiger, Olaf Simons and Lucas Werkmeister for their support.